| |
Меня часто спрашивают: чем ты занимаешься? В чем заключается твоя работа? Как проводятся генетические тесты глазных болезней? Как давно их начали проводить? В каком направлении сегодня движется развитие технологий генетической диагностики? В чем преимущества того или иного способа? Каковы основные тренды?
Поэтому я решила пошагово ответить на эти вопросы и описать, в чем же собственно смысл генетической диагностики глаз. Вот реальный случай из моей клинической практики. Молодые активные родители, мама и папа абсолютно здоровы, ребенку 1 годик, по клиническим признакам ставят редкий диагноз, ребенок абсолютно слеп, не различает контуры предметов. Раньше врачи убедили бы родителей, что действенными методами возвращать зрение нынешняя медицина не обладает. А сейчас веры и силы воли родителей хватило для того, чтобы перерыть всю информацию в Интернете, посетить все ведущие медучреждения, занимающиеся данной патологией, уже сегодня докопаться до одной наиболее вероятной причины неспособности своего ребенка видеть, они провели всевозможные тесты и нашли поломку одного из генов. Их поиски методов лечения данной поломки пока не увенчались успехом. Клиническое испытание по данному заболеванию планируется начать в одном из центров Европы только через 2 года. Значит, есть шанс, что через 5-7 лет на рынке появится действенное средство от болезни, ранее считавшейся неизлечимой.
Это один из множества примеров. Сейчас ученые достигли больших успехов в лечении редких, однофакторных болезней, где причина одна и она ясна. В будущем, когда разберемся с редкими, так называемыми «моногенными» заболеваниями, нам будет легче перейти к лечению более частых, многофакторных, запутанных заболеваний.
С чего все начиналось?
О генетических методах лечения стали говорить еще в 1960-х после открытия двуспиральной ДНК биологами Уотсоном и Криком. В 1970-х появился революционный метод Сенгера для определения последовательности нуклеотидов в гене, что привело к накоплению и пониманию большого количества информации. Но самых больших результатов в ДНК диагностике и лечении человечество достигло в последние 10 лет, применяя нарастающие по экспоненте скорости обработки данных, их хранение и обработку. Нашумевший проект «Геном человека», когда научные центры нескольких стран объединили свои усилия, стал отправной точкой для понимания множества механизмов работы человеческого тела и дал людям осознание, что человечество способно работать в команде на уровне всей планеты и способно охватывать разумом такое количество информации, которое раньше считалось невозможным.
Дело в том, что для генетики нет границ: глазное, эндокринное или сердечное заболевание. Есть последовательность из четырех видов нуклеотидов: A , C , G , T («букв»), всего 3 миллиарда пар нуклеотидов. По алгоритму, заложенному в этих буквах, и строится наше тело. А вот к какому комплексу патологий приведет перестановка (мутация) той или иной буквы кода нашего тела, разбирается уже клиницист определенной специальности при обращении конкретного пациента с конкретной проблемой. Поэтому здесь важно понимать, что необходимо работать в команде клиницистов, генетиков, молекулярных биологов, технологов и программистов. Моя специализация – глазные проявления генетических перестановок.
Как проводят генетическую диагностику?
Во-первых, необходимо получить биологический материал, содержащий достаточно клеток с ДНК. Это может быть кровь, эпителий со внутренней поверхности щеки, слюна, ногти, волосы, биоптат тканей и пр. Наиболее удобна в данном случае кровь, потому что она содержит много клеток с ДНК, в отличие от слюны или эпителия со щеки, а также в ней меньше чужеродных организмов (бактерий, например). Однако для разных тестов могут больше подходить разные биоматериалы.
Во-вторых, из полученного биоматериала необходимо выделить достаточное для анализа количество ДНК. Это тоже целая наука, основные способы которой уже отработаны, понятны и не представляют сложности при соблюдении технологии.
В-третьих, нужно выбрать метод анализа ДНК: их очень много, у каждого свои особенности. Технологии, лежащие в их основе, гениальны, виртуозны, часто просты и восхищают тем, до чего только может додуматься человек, когда работает с чем-то, что не может ни пощупать, ни понюхать, ни увидеть. Подробнее об этом можно узнать здесь: oftalmic.ru/technology.php. Скажу только, что наиболее часто используемые сейчас методы – это секвенирование (узнавание последовательности нуклеотидов в гене) нового поколения (NGS), классическое секвенирование по Сенгеру и ПЦР в реальном времени. Итак, специалисты выбрали метод, которым они провели анализ и получили результат теста. В идеале – это точная последовательность нуклеотидов в гене, прочитанная без ошибок.
В-четвертых, нужно разобрать полученный результат «по буквам» и сказать пациенту, что же именно в его случае привело к болезни. Вот на этом этапе рухнули многочисленные ожидания «чудес» медицины нового тысячелетия. Что делать с полученным результатом, он явно ценен, но как понять эту шифровку? Как его применять с пользой для пациента?

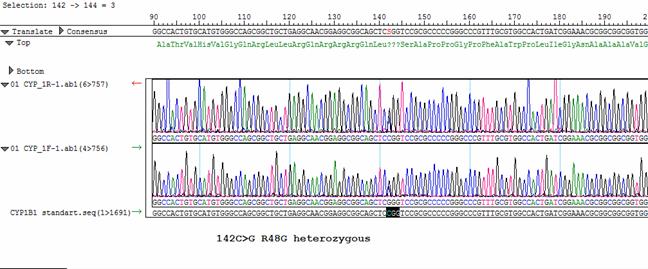
Здесь мы похожи на мартышку с айфоном, зато мы честно признаемся в том, что знаем мало и стараемся узнать больше. Вот клинический пример. На картинке приведена последовательность одного из моих генов:
Цветные пики соответствуют типу нуклеотида в определенной позиции: аденин, тимин, гуанин и цитозин, это результат секвенирования по Сенгеру. Черным показана значимая мутация в моем гене. К счастью, только в одной из двух копий, то есть мутация гетерозиготна – сломана только одна копия гена, а не обе. В результате синтезируется белок с неправильной структурой. Что это значит? К чему это приведет? В точности мы пока не знаем. Как узнать? Узнать точно можно только сложив полностью мозаику, которой мы по сути являемся.
В базе данных GenBank в открытом доступе лежит вся информация, полученная во всем мире о нормальном геноме и известных на сегодняшний день мутациях и их влиянии на здоровье. Таким образом, мы, получив сиквенс (последовательность), сравниваем его с нормой ( refseq – reference sequence ), изучаем информацию о найденных мутациях, если они есть, и на основании этого анализа делаем заключение: связано развитие болезни с этой мутацией или нет.
Сложность в том, что уже опубликованы сотни тысяч статей о найденных единичных мутациях. Пока еще никто в мире четко не представляет, каким же способом анализировать взаимосвязи и взаимовлияние мутаций в разных генах. Для этого нужны супераналитики, суперкомпьютеры, суперпрограммисты. Причем даже суперпрограммисты не помогут, если супераналитики (это очень общее определение, как вы понимаете) не поставят программистам четкую задачу: что же все-таки нужно искать и вычленять в этой базе данных.
Добавлю информации к размышлению: не только геномные аномалии ведут к болезни, но и эпигеномные взаимодействия. То есть иногда, даже при четко доказанной мутации, болезнь не проявляется, так как присутствуют какие-то компенсирующие ее механизмы (на уровне над-геномного взаимодействия), иногда одна и та же мутация приводит к абсолютно разным болезням. Иногда мутации в сотне разных генов приводят к одной и той же болезни. Окончательно ошеломившим меня фактором явилось то, что у каждой популяции людей свой набор мутаций, например, японские тест-системы для россиян не подойдут, даже супер-качественные, потому что они определяют те мутации, которых почти нет у россиян! У нас свои собственные, пока еще никому не известные. Единственный способ – создать свои системы на основе анализа данных российской популяции.
Дорогое удовольствие?
ПЦР (полимеразно-цепная реакция) в реальном времени является отличным недорогим способом для поиска замен «букв» в известной позиции гена. А что делать, если мы не знаем, в какой позиции произошла мутация? Мы знаем только ген, в котором она наиболее вероятна. Зная ген болезни, мы можем полностью просеквенировать его, например, по Сенгеру. Тоже довольно точный, удобный и недорогой способ для коротких генов. Но часто мы не знаем не только в какой позиции, но и в каком гене произошла мутация, а имеем только предположительный набор генов, в которых мутация наиболее вероятна при данных проявлениях болезни. Что делать в таком случае? Если секвенировать приходится несколько десятков генов и если гены длинные, то цена за анализ методом Сенгера может быть более 300 тысяч рублей (подробнее о том, почему).
В таком случае встает очевидный вопрос: если просеквенировать все гены сразу (всего их около 25000) с помощью секвенирования нового поколения стоит 300 тысяч рублей, то зачем секвенировать только эти 20 генов за те же 300 тысяч, может, тогда быстрее, проще и дешевле сделать анализ всех генов сразу, тогда мы получим более богатый исходный материал и сможем если не сейчас, то когда накопятся нужные данные, проанализировать гены, не делая этот дорогой тест повторно, а просто используя полученные ранее результаты.
Вот это идея! Имея представление о том, как проводится секвенирование по Сенгеру, я решила узнать, как же выглядят результаты полногеномного секвенирования, чтобы представить, как с ними можно работать. Самым многообещающим аппаратом на рынке полногеномного секвенирования (хотя их несколько разных видов и технологий) считается аппарат марки Illumina (Иллюмина). Он довольно дорогой, в Москве есть несколько таких аппаратов в разных учреждениях. Мне давно хотелось посмотреть, как выглядит геном (геном – совокупность всех генов, определяющая свойства человека, это последовательность из трех миллиардов букв A , C , G , T ). Если не удастся посмотреть на геном, то хотя бы на экзом (экзом – совокупность всех частей генов, экзонов, с которых идет синтез белков – кирпичиков тела человека, что составляет 1 – 2% от всего генома). Как это выглядит после анализа образца крови на Иллюмине? С чем предстоит работать? Все говорят: «Иллюмина, Иллюмина, купил ее за миллион долларов и все проблемы решены». Однако с ее покупкой они только начнутся. То, что я увидела, превзошло все мои ожидания.
Представьте себе текстовый файл, где массив сформирован в группы по 4 строки, первая строка – код дорожки чипа, вторая строка – непосредственно последовательность нуклеотидов (короткая цепочка 25-50 букв), третья строка – степень достоверности прочтения каждого нуклеотида и четвертая строка – количество перекрываний и прямое или обратное это считывание. Приблизительно так:
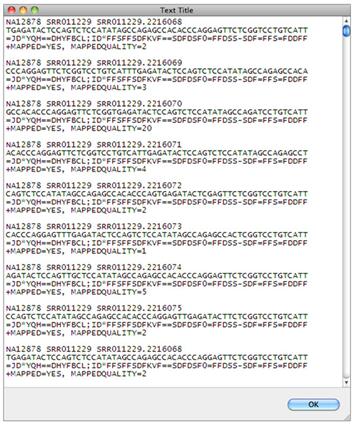
Данный текстовый файл весит 28 гигабайт!!! О! Вот вы его получили, распечатали для пациента, чтобы он понял, за что заплатил деньги (толщина книги получится больше 5-и метров и этот пациент перестанет быть вашим пациентом, он пойдет к хирургу с грыжей). Вот результат. Пожалуйте! Следующий вопрос: что делать с этим файлом?
Если вы секвенируете старым способом по Сенгеру отдельные гены, то опытным взглядом можете посмотреть на буквы и сказать: «О, это мой сиквенс, эти гены мне знакомы». На Иллюмине жизни не хватит, чтобы просто просмотреть весь этот файл глазами.
Я уверена, что со временем мы научимся работать с такого рода массивами данных, потому что опыт человечества в этом вопросе с каждым днем растет. Причем нужно учесть, что здесь, по сути, не важна исходная область получения данных: финансовые, математические или медицинские массивы данных. Вот мы и дошли до вопросов: в каком направлении сегодня движется развитие технологий генетической диагностики? В чем преимущества того или иного способа? Каковы основные тренды? Теперь, представляя себе предмет исследования, вы можете по-разному ответить на эти вопросы. Все зависит от ваших целей. Моей целью является data mining – то есть создание клинически полезной информации из массивов данных генома в области глазных заболеваний.
Из полученного файла сначала нужно сформировать контиги - "склеить" в цепочку короткие фрагменты (25 - 50 нуклеотидов) генов. Затем нужно вычленить из полученного массива данных необходимые в определенном клиническом случае гены, собрать достоверно имеющиеся точечные мутации, соотнести их с базой данных всех людей, для которых полученая эта информация, статистическими методами определить наиболее вероятные мутации, приведшие к заболеванию. Клиническое заключение по данным генетического анализа
На основе имеющихся в мире данных о достоверных взаимосвязях между мутацией и болезнью мы разрабатываем малого объема тесты, например, выявляем наличие или отсутствие трех точечных мутаций в гене, которые очень часто приводят к болезни. По мере накопления знаний об особенностях российской популяции мы расширяем, улучшаем и уточняем уже имеющиеся у нас тесты, а также разрабатываем новые. В таком случае мы с большей вероятностью дадим достоверные клинически полезные сведения для лечения пациента. Задать вопрос
(c) Марианна Иванова, ноябрь 2012 |
|